
티스토리 뷰
Getting Start
IOT(Internet Of Things : 사물인터넷) 프로젝트를 진행하게 되면서 Influx DB라는 시계열 데이터베이스(TSDB : Time-series Database)를 사용해 보았습니다. 최신 트렌트로 빅데이터가 등장했으며 앞으로도 시계열 데이터베이스가 중용되어질 것이라는 개인적인 생각이 듭니다. IOT의 경우, 각 디바이스들로 부터 시시각각 각종 데이터들(예를 들면, 공기, 수질, 전기 등)을 초, 분, 시간 단위로 수집이 되기 때문에 수집 데이터베이스에 특화된 시계열 데이터베이스를 사용하게 되었습니다. 시계열 데이터베이스에는 Open TSDB, Influx DB, Graphite 등이 있으며, 그 중 Influx DB를 사용한 경험에 대해서 공유드리려고 합니다.

(influx db 로고...)
아키텍처
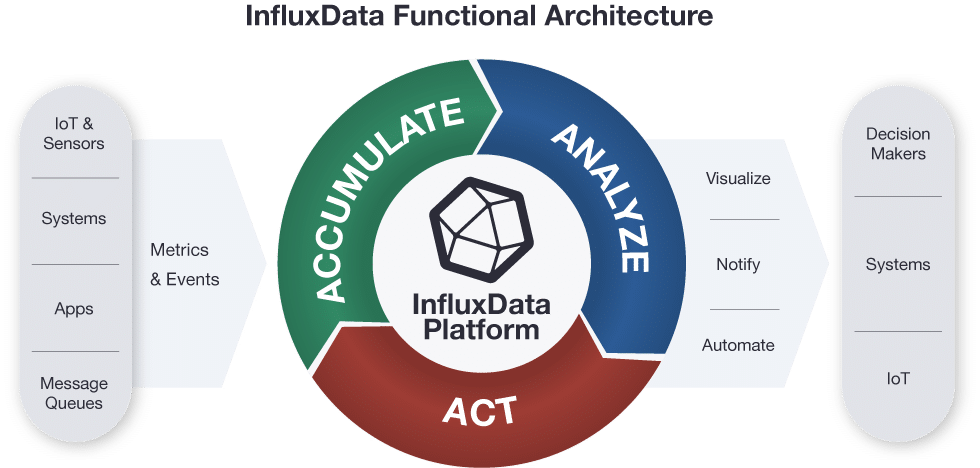
IoT 센서 데이터 수집과 이벤트 처리에 가장 범용적으로 사용되며, 실시간 스트림 분석 등의 작업을 수행하는 것이 가능합니다.
설치
현재 Mac OS를 사용하고 있기에 간단하게 brew를 사용해서 설치를 진행해 줍니다. 설치를 하게 되면 아래와 같은 로그를 확인해 보실 수 있습니다.
> brew update
> brew install influxdb
다른 OS에서 설치를 희망하신 경우 다음의 링크로 접속해서 해당 OS에 맞는 설치 방법을 더욱 자세하게 확인해보실 수 있습니다.
설치 완료 후, 개인 로컬 서버에서 테스트를 위해 기동을 위해 다음 명령어를 실행합니다.
> brew services start influxdb위 단계를 통해 influx db를 실행했으며, 다음 명령어 문법을 사용해 influx db에 접속을 시도합니다. ( influx db 기본 포트 : 8086 )
influx \
-precision 'rfc3339' \
-host '[호스트]' -port '[포트번호]' \
-username '[유저네임]' -password '[비밀번호; 비워두면 물어봄]' \
-database '[데이터베이스 이름]'가장 디폴트로 접속 후, show databases 명령어를 실행했을 때, 다음과 같은 화면을 확인 할 수 있습니다.

기본 개념 정리
influx db는 기본적으로 MySQL등에서 사용되는 SQL문을 완전히는 아니지만 어느정도 유사하게 사용할 수 있는 메리트가 있으나 기본적인 개념에서 조금 차이가 나는 부분이 있어 잘 정리된 Document를 확인해볼 필요가 있습니다.
기본적으로 RDB와의 용어를 비교된 아래 표를 확인해보시면 됩니다.
| RDB | Influx DB |
| database | database |
| table | measurement |
| column | key |
| PK or indexed column | tag key (only string) |
| unindexed column | field key |
| SET of index entries | series |
기본적으로 데이터베이스는 동일하게 데이터베이스를 사용하고 있으며, RDB에서의 테이블은 측정 데이터의 의미를 가진 Measurement 로 대응됩니다. 그리고 각 컬럼들은 key라고 불려지는데, 여기서 tag key와 field key로 구분이 되어집니다. field key의 경우에는 주로 측정된 데이터들을 의미하며 예를 들면, 온도나 습도 등이 해당 될 수 있습니다. tag key의 경우에는 field key를 제외한 데이터들이라고 쉽게 이해하시면 될 것 같습니다.
Query 작성
기본적인 데이터베이스를 하나 구성하기 위해 다음과 같은 명령어로 데이터베이스를 생성합니다. 그리고, 생성된 데이터베이스 조회를 진행하면 아래의 이미지와 같은 형태로 생성된 데이터베이스 목록을 확인해 볼 수 있습니다.
> create database test_db
> show databases
데이터베이스 사용을 위해 use test_db 명령어를 실행 후, 초기에는 생성된 Measurement가 없기 때문에 insert 문을 사용해 테스트를 위한 데이터를 실행해 줍니다. insert 문법은 다음과 같습니다.
|
INSERT [measurement 이름], [태그 이름1]=[태그 값1], [태그 이름2]=[태그 값2] [필드 이름1]=[필드 값1], [필드 이름2]=[필드 값2] |
그리고, 생성된 Measurement 및 데이터를 확인하기 위해서는 select sql 문법을 사용하시면 됩니다.
> insert test_measurement,test_tag='test11',tag2='test22' field1=89,field2=99
> select * from test_measurement
인증
influx db의 인증을 설정하기 위해서는 우선 현재 접속된 influx db에서 유저를 다음과 같이 원하는 유저로 생성을 진행합니다.
> CREATE USER <username> WITH PASSWORD <password> WITH ALL PRIVILEGES
> GRANT ALL PRIVILEGES TO <username> 그리고, brew로 설치를 진행했을 경우 /usr/local/etc/influxdb.conf 파일을, 다른 os에서 진행했을 경우 설치 위치의 influxdb.conf 파일의 auth-enabled를 true로 변경을 진행하면, 로그인을 해야만 해당 기능을 사용할 수 있게 구성이 됩니다.
[http]
# Determines whether HTTP endpoint is enabled.
# enabled = true
# Determines whether the Flux query endpoint is enabled.
# flux-enabled = false
# Determines whether the Flux query logging is enabled.
# flux-log-enabled = false
# The bind address used by the HTTP service.
# bind-address = ":8086"
# Determines whether user authentication is enabled over HTTP/HTTPS.
auth-enabled = trueJava 연동
위에서 설치 및 구성을 한 influx db를 자바 코드 상에서 데이터 수집, 조회의 목적을 위해서 사용할 수 있으며, 자바 개발자들로 하여금 익숙한 자바 코드를 사용해 influx db에 데이터를 삽입 및 조회를 진행 할 수 있습니다. 아래의 순서에 따라 진행하시면 매우 쉽게 인플럭스 DB와 자바와의 연동을 쉽게 처리할 수 있습니다.
우선, influx db를 자바와 연동을 위해선 다음과 같이 influx db 디펜던시를 pom.xml에 추가해줍니다.
<!-- https://mvnrepository.com/artifact/org.influxdb/influxdb-java -->
<dependency>
<groupId>org.influxdb</groupId>
<artifactId>influxdb-java</artifactId>
<version>2.17</version>
</dependency>그리고, influx db의 기본 접속 정보(URL, username, password, database)를 application.yml 파일에 정리해서 기술합니다.
spring:
influxdb:
url: http://localhost:8086
username: *****
password: *****
database: test_db
retention-policy: autogeninflux db 자바 코드를 사용할 수 있도록 config를 다음과 같이 구성합니다.
@Configuration
@EnableConfigurationProperties(InfluxDBProperties.class)
public class InfluxDbConfig {
@Bean
public InfluxDBConnectionFactory connectionFactory(final InfluxDBProperties properties) {
return new InfluxDBConnectionFactory(properties);
}
@Bean
public InfluxDBTemplate<Point> influxDBTemplate(
final InfluxDBConnectionFactory connectionFactory) {
/*
* You can use your own 'PointCollectionConverter' implementation, e.g. in case
* you want to use your own custom measurement object.
*/
return new InfluxDBTemplate<>(connectionFactory, new PointConverter());
}
@Bean
public DefaultInfluxDBTemplate defaultTemplate(
final InfluxDBConnectionFactory connectionFactory) {
/*
* If you are just dealing with Point objects from 'influxdb-java' you could
* also use an instance of class DefaultInfluxDBTemplate.
*/
return new DefaultInfluxDBTemplate(connectionFactory);
}
}테스트
위에서 구성한 influx db와 자바와의 연동을 테스트 하기 위해서 아래와 같이 테스트 코드를 작성해서 테스트를 진행했습니다. 테스트로 loop를 10번 돌면서 데이터를 insert 하도록 했습니다.
@SpringBootTest
@RunWith(SpringJUnit4ClassRunner.class)
public class InfluxDBTest {
private final static Logger logger = LoggerFactory.getLogger(InfluxDBTest.class);
@Autowired
private InfluxDBTemplate<Point> influxDBTemplate;
@Test
public void writeData() {
for (int index = 1; index <= 10; index++) {
Point point = Point.measurement("test_measurement")
.time(System.currentTimeMillis(), TimeUnit.MILLISECONDS)
.addField("field1", index)
.addField("field2", 100 + index)
.addField("tag2", "test" + index)
.addField("test_tag", "test" + 100 + index)
.build();
influxDBTemplate.write(point);
}
}
}테스트를 수행 후 데이터가 정상적으로 들어갔는지 확인을 위해 influx db 접속 후, 조회를 해보면 아래와 같이 정상적으로 데이터가 들어간 것을 확인 할 수 있습니다.

자바 코드로 테스트를 수행한 데이터를 확인 하기 위해, 조회 용 자바 코드를 아래와 같이 구성해서 테스트를 진행해봤습니다. 우선 조회를 위해 해당 데이터들이 매핑이 될 수 있도록 도메인을 만들어 줍니다.
@Measurement(name = "test_measurement")
public class TestMeasurement {
@Column(name = "time")
private Instant time;
@Column(name = "field1")
private int field1;
@Column(name = "field2")
private int field2;
@Column(name = "tag2")
private String tag2;
@Column(name = "test_tag")
private String testTag;
@Override
public String toString() {
return "TestMeasurement {" +
"time=" + time +
", field1=" + field1 +
", field2=" + field2 +
", tag2='" + tag2 + '\'' +
", testTag='" + testTag + '\'' +
'}';
}
}위에서 생성한 도메인을 기준으로 pojo로 데이터들이 매핑이 이루어집니다.
@SpringBootTest
@RunWith(SpringJUnit4ClassRunner.class)
public class InfluxDBTest {
private final static Logger logger = LoggerFactory.getLogger(InfluxDBTest.class);
@Autowired
private InfluxDBTemplate<Point> influxDBTemplate;
@Test
public void selectData() {
Query query = QueryBuilder.newQuery("SELECT * FROM test_measurement")
.forDatabase("test_db")
.create();
QueryResult queryResult = influxDBTemplate.query(query);
InfluxDBResultMapper resultMapper = new InfluxDBResultMapper(); // thread-safe - can be reused
List<TestMeasurement> testMeasurementList = resultMapper.toPOJO(queryResult, TestMeasurement.class);
for (TestMeasurement tm : testMeasurementList) {
System.err.println(tm.toString());
}
}
}조회 용 코드를 수행한 결과는 아래와 같습니다. toString() 을 통해 리스트를 콘솔에 표현했습니다.

참고 사이트
- Total
- Today
- Yesterday